OneSearch (baseline):V1 基线模型,作为所有实验对照基准。
+ CoT tasks:SFT Stage 1 引入四项 CoT 任务后 Order HR@10 +0.48%,验证关键词级 CoT 对 query 语义歧义的有效缓解。
+ self-distill:单项最大提升(Order HR@10 +1.17%,Click HR@10 +1.67%),确认将推理能力编码进权重是主要驱动。
+ R-Drop:MRR@10 由 0.1017 升至 0.1045,预测一致性约束有效缓解信息不对称导致的输出分布波动。
+ FGM:Order HR@10 升至 0.2180,Click HR@10 升至 0.2422,输入鲁棒性进一步增强。
+ focal loss:缓解 SID 长尾类别不均衡,Order HR@10 达 0.2214,Click HR@10 达 0.2471,三种正则化组合效果超过各自贡献之和,SFT 阶段收尾。
+ PARS:V1 原有自适应奖励系统作 RL 基线,Click HR@10 0.2538,但 Order MRR@10 相对偏低。
+ GRPO:替换 PARS 后 Order HR@10 0.2248、MRR@10 0.1106,验证复合奖励与组相对优化。
+ TPMA:Order MRR@10 进一步升至 0.1136,体现层次化信用分配对细粒度 token 生成的增益。
OneSearch-V2:Listwise DPO + TPMA-GRPO 联合优化,达全指标最优(Order HR@10 0.2314,Click HR@10 0.2568),相比 baseline 平均 HR@10 +2.68%、MRR@10 +1.66%。DPO 学基础偏好拟合、TPMA 平衡多维奖励与泛化,二者互补达到最佳效果。


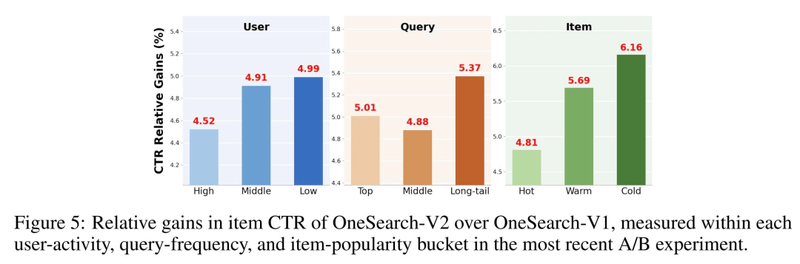
全部评论